Way to go! You have already learnt a lot of essential components of the Python language. Being able to deal with data structures, import packages, build your own functions and operate with files is not only essential for most tasks in Python, but also a prerequisite for text analysis. We have applied some common preprocessing steps like casefolding/lowercasing, punctuation removal and stemming/lemmatization. Did you know that there are some very useful NLP packages and modules that do some of these steps? One that is often used in text analysis is the Python package NLTK (the Natural Language Toolkit).
If you have any questions about this chapter, please refer to forum on Canvas
There are many aspects of text we can (try to) analyze. Commonly used analyses conducted in Natural Lanugage Processing (NLP) are for instance:
...and many more. Each of these aspects is addressed within its own NLP task.
The NLP pipeline
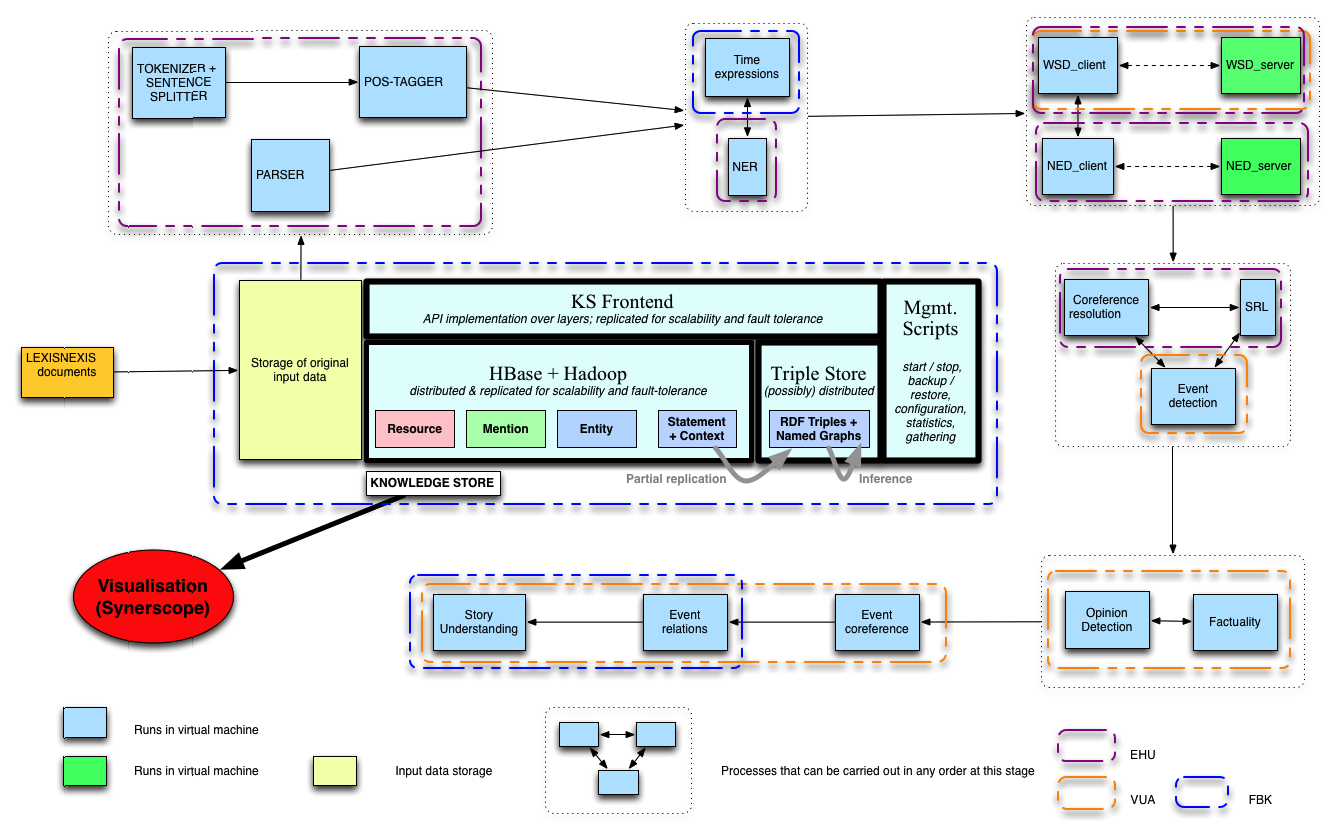
Usually, these tasks are carried out sequentially, because they depend on each other. For instance, we need to first tokenize the text (split it into words) in order to be able to assign part-of-speech tags to each word. This sequence is often called an NLP pipeline. For example, a general pipeline could consist of the components shown below (taken from here) You can see the NLP pipeline of the NewsReader project here. (you can ignore the middle part of the picture, and focus on the blue and green boxes in the outer row).
In this chapter we will look into four simple NLP modules that are nevertheless very common in NLP: tokenization, sentence splitting, lemmatization and POS tagging.
There are also more advanced processing modules out there - feel free to do some research yourself :-)
NLTK (Natural Language Processing Toolkit) is a module we can use for most fundamental aspects of natural language processing. There are many more advanced approaches out there, but it is a good way of getting started.
Here we will show you how to use it for tokenization, sentence splitting, POS tagging, and lemmatization. These steps are necessary processing steps for most NLP tasks.
We will first give you an overview of all tasks and then delve into each of them in more detail.
Before we can use NLTK for the first time, we have to make sure it is downloaded and installed on our computer (some of you may have already done this).
To install NLTK, please try to run the following 2 cells. If this does not work, please try and follow the documentation. If you don't manage to get this to work, please ask for help.
In [ ]:
%%bash
pip install nltk
In [ ]:
# downloading nltk
import nltk
nltk.download('book')
Now that we have installed and downloaded NLTK, let's look at an example of a simple NLP pipeline. In the following cell, you can observe how we tokenize raw text into tokens and setnences, perform part of speech tagging and lemmatize some of the tokens. Don't worry about the details just yet - we will go trhough them step by step.
In [ ]:
text = "This example sentence is used for illustrating some basic NLP tasks. Language is awesome!"
# Tokenization
tokens = nltk.word_tokenize(text)
# Sentence splitting
sentences = nltk.sent_tokenize(text)
# POS tagging
tagged_tokens = nltk.pos_tag(tokens)
# Lemmatization
lmtzr = nltk.stem.wordnet.WordNetLemmatizer()
lemma=lmtzr.lemmatize(tokens[4], 'v')
# Printing all information
print(tokens)
print(sentences)
print(tagged_tokens)
print(lemma)
Now, let's try tokenizing our Charlie story! First, we will open and read the file again and assign the file contents to the variable content. Then, we can call the word_tokenize() function from the nltk module as follows:
In [ ]:
with open("../Data/Charlie/charlie.txt") as infile:
content = infile.read()
tokens = nltk.word_tokenize(content)
print(tokens)
As you can see, we now have a list of all words in the text. The punctuation marks are also in the list, but as separate tokens.
Another thing that NLTK can do for you is to split a text into sentences by using the sent_tokenize() function. We use it on the entire text (as a string):
In [ ]:
with open("../Data/Charlie/charlie.txt") as infile:
content = infile.read()
sentences = nltk.sent_tokenize(content)
print(sentences)
We can now do all sorts of cool things with these lists. For example, we can search for all words that have certain letters in them and add them to a list. Let's say we want to find all present participles in the text. We know that present participles end with -ing, so we can do something like this:
In [ ]:
# Open and read in file as a string, assign it to the variable `content`
with open("../Data/Charlie/charlie.txt") as infile:
content = infile.read()
# Split up entire text into tokens using word_tokenize():
tokens = nltk.word_tokenize(content)
# create an empty list to collect all words having the present participle -ing:
present_participles = []
# looking through all tokens
for token in tokens:
# checking if a token ends with the present parciciple -ing
if token.endswith("ing"):
# if the condition is met, add it to the list we created above (present_participles)
present_participles.append(token)
# Print the list to inspect it
print(present_participles)
This looks good! We now have a list of words like boiling, sizzling, etc. However, we can see that there is one word in the list that actually is not a present participle (ceiling). Of course, also other words can end with -ing. So if we want to find all present participles, we have to come up with a smarter solution.
Once again, NLTK comes to the rescue. Using the function pos_tag(), we can label each word in the text with its part of speech.
To do pos-tagging, you first need to tokenize the text. We have already done this above, but we will repeat the steps here, so you get a sense of what an NLP pipeline may look like.
To see how pos_tag() can be used, we can (as always) look at the documentation by using the help() function. As we can see, pos_tag() takes a tokenized text as input and returns a list of tuples in which the first element corresponds to the token and the second to the assigned pos-tag.
In [ ]:
# As always, we can start by reading the documentation:
help(nltk.pos_tag)
In [ ]:
# Open and read in file as a string, assign it to the variable `content`
with open("../Data/Charlie/charlie.txt") as infile:
content = infile.read()
# Split up entire text into tokens using word_tokenize():
tokens = nltk.word_tokenize(content)
# Apply pos tagging to the tokenized text
tagged_tokens = nltk.pos_tag(tokens)
# Inspect pos tags
print(tagged_tokens)
As we saw above, pos_tag() returns a list of tuples: The first element is the token, the second element indicates the part of speech (POS) of the token.
This POS tagger uses the POS tag set of the Penn Treebank Project, which can be found here. For example, all tags starting with a V are used for verbs.
We can now use this, for example, to identify all the verbs in a text:
In [ ]:
# Open and read in file as a string, assign it to the variable `content`
with open("../Data/Charlie/charlie.txt") as infile:
content = infile.read()
# Apply tokenization and POS tagging
tokens = nltk.word_tokenize(content)
tagged_tokens = nltk.pos_tag(tokens)
# List of verb tags (i.e. tags we are interested in)
verb_tags = ["VBD", "VBG", "VBN", "VBP", "VBZ"]
# Create an empty list to collect all verbs:
verbs = []
# Iterating over all tagged tokens
for token, tag in tagged_tokens:
# Checking if the tag is any of the verb tags
if tag in verb_tags:
# if the condition is met, add it to the list we created above
verbs.append(token)
# Print the list to inspect it
print(verbs)
We can also use NLTK to lemmatize words.
The lemma of a word is the form of the word which is usually used in dictionary entries. This is useful for many NLP tasks, as it gives a better generalization than the strong a word appears in. To a computer, cat and cats are two completely different tokens, even though we know they are both forms of the same lemma.
We will use the WordNetLemmatizer for this using the lemmatize() function. In the code below, we loop through the list of verbs, lemmatize each of the verbs, and add them to a new list called verb_lemmas. Again, we show all the processing steps (consider the comments in the code below):
In [ ]:
#################################################################################
#### Process text as explained above ###
with open("../Data/Charlie/charlie.txt") as infile:
content = infile.read()
tokens = nltk.word_tokenize(content)
tagged_tokens = nltk.pos_tag(tokens)
verb_tags = ["VBD", "VBG", "VBN", "VBP", "VBZ"]
verbs = []
for token, tag in tagged_tokens:
if tag in verb_tags:
verbs.append(token)
print(verbs)
#############################################################################
#### Use the list of verbs collected above to lemmatize all the verbs ###
# Instatiate a lemmatizer object
lmtzr = nltk.stem.wordnet.WordNetLemmatizer()
# Create list to collect all the verb lemmas:
verb_lemmas = []
for participle in verbs:
# For this lemmatizer, we need to indicate the POS of the word (in this case, v = verb)
lemma = lmtzr.lemmatize(participle, "v")
verb_lemmas.append(lemma)
print(verb_lemmas)
Note about the wordnet lemmatizer:
We need to specify a POS tag to the WordNet lemmatizer, in a WordNet format ("n" for noun, "v" for verb, "a" for adjective). If we do not indicate the Part-of-Speech tag, the WordNet lemmatizer thinks it is a noun (this is the default value for its part-of-speech). See the examples below:
In [ ]:
test_nouns = ('building', 'applications', 'leafs')
for n in test_nouns:
print(f"Noun in conjugated form: {n}")
default_lemma=lmtzr.lemmatize(n) # default lemmatization, without specifying POS, n is interpretted as a noun!
print(f"Default lemmatization: {default_lemma}")
verb_lemma=lmtzr.lemmatize(n, 'v')
print(f"Lemmatization as a verb: {verb_lemma}")
noun_lemma=lmtzr.lemmatize(n, 'n')
print(f"Lemmatization as a noun: {noun_lemma}")
print()
In [ ]:
test_verbs=('grew', 'standing', 'plays')
for v in test_verbs:
print(f"Verb in conjugated form: {v}")
default_lemma=lmtzr.lemmatize(v) # default lemmatization, without specifying POS, v is interpretted as a noun!
print(f"Default lemmatization: {default_lemma}")
verb_lemma=lmtzr.lemmatize(v, 'v')
print(f"Lemmatization as a verb: {verb_lemma}")
noun_lemma=lmtzr.lemmatize(v, 'n')
print(f"Lemmatization as a noun: {noun_lemma}")
print()
The WordNet lemmatizer assumes every word is a noun unless specified diferently. We need to be careful and specify the POS tag because otherwise we will end up with wrong lemmatization such as the cases shown in the past two cells. For example, by default WordNet thinks that "grew" is a noun, and it will not lemmatize it as a past-tense verb.
Luckily, we learned that we can also automatically infer the POS tags for each word. We can use these automatic POS tags as input to our lemmatizer to improve its accuracy for non-nouns. As an intermediate step, we need to translate the POS tags that we get from our POS tagger (this are according to the Penn TreeBank classification) to WordNet POS tags. Here is an example of how to lemmatize your words in a proper way, accounting for different POS tags (you can also read this discussion):
In [ ]:
# Lemmatizing (the proper way, accounting for different POS tags)
from nltk.corpus import wordnet as wn
# We can write a general function to translate penn tree bank tags to wordnet tags
def penn_to_wn(penn_tag):
"""
Returns the corresponding WordNet POS tag for a Penn TreeBank POS tag.
"""
if penn_tag in ['NN', 'NNS', 'NNP', 'NNPS']:
wn_tag = wn.NOUN
elif penn_tag in ['VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ']:
wn_tag = wn.VERB
elif penn_tag in ['RB', 'RBR', 'RBS']:
wn_tag = wn.ADV
elif penn_tag in ['JJ', 'JJR', 'JJS']:
wn_tag = wn.ADJ
else:
wn_tag = None
return wn_tag
lmtzr = nltk.stem.wordnet.WordNetLemmatizer()
# create empty list to collect lemmas
lemmas = list()
# We use the tagged tokens we collected above and loop through the list of tuples
for token, pos in tagged_tokens:
# convert Penn Treebank POS tag to WordNet POS tag
wn_tag = penn_to_wn(pos)
# we check if a wordnet tag was assigned
if not wn_tag == None:
# we lemmatize using the translated wordnet tag
lemma = lmtzr.lemmatize(token, wn_tag)
else:
# if there is no wordnet tag, we apply default lemmatization
lemma = lmtzr.lemmatize(token)
# add lemmas to list
lemmas.append(lemma)
# Inspect lemmas by printing them
print(lemmas)
So far we typically used a single for-loop or we were opening a single file at a time. In Python (and most programming languages), one can nest multiple loops or files in one another. For instance, we can use one (external) for-loop to iterate through files, and then for each file iterate through all its sentences (internal for-loop). As we have learned above, glob is a convenient way of creating a list of files.
You might think: can we stretch this on more levels? Iterate through files, then iterate through the sentences in these files, then iterate through each word in these sentences, then iterate through each letter in these words, etc. This is possible. Python (and most programming languages) allow you to perform nesting with (in theory) as many loops as you want. Keep in mind that nesting too much will eventually cause computational problems, but this depends also on the size of your data.
In the code below, we want get an idea of the number and length of the sentences in the texts stored in the ../Data/dreams directory. We do this by creating two for loops: We iterate over all the files in the directory (loop 1), apply sentence tokenization and iterate over all the sentences in the file (loop 2).
Look at the code and comments below to figure out what is going on:
In [ ]:
import glob
### Loop 1 ####
# Loop1: iterate over all the files in the dreams directory
for filename in glob.glob("../Data/dreams/*.txt"):
# read in the file and assign the content to a variable
with open(filename, "r") as infile:
content = infile.read()
sentences = nltk.sent_tokenize(content) # split the content into sentences
print(f"INFO: File {filename} has {len(sentences} sentences") # Print the number of sentences in the file
# For each file, assign a number to each sentence. Start with 0:
counter=0
#### Loop 2 ####
# Loop 2: loop over all the sentences in a file:
for sentence in sentences:
counter+=1 # add 1 to the counter
tokens=nltk.word_tokenize(sentence) # tokenize the sentence
print("Sentence %d has %d tokens" % (counter, len(tokens))) # print the number of tokens per sentence
# print an empty line after each file (this belongs to loop 1)
print()
In this section, we will use what we have learned above to write a small NLP program. We will go through all the steps and show how they can be put together. In the last chapters, we have already learned how to write functions. We will make use of this skill here.
Our goal is to collect all the nouns from Vickie's dream reports.
Before we write actual code, it is always good to consider which steps we need to carry out to reach the goal.
Important steps to remember:
Remember, we first needed to import nltk to use it.
Since we want to carry out the same task for each of the files, it is very useful (and good practice!) to write a single function which can do the processing. The following function reads the specified file and returns the tokens with their POS tags:
In [ ]:
import nltk
def tag_tokens_file(filepath):
"""Read the contents of the file found at the location specified in
FILEPATH and return a list of its tokens with their POS tags."""
with open(filepath, "r") as infile:
content = infile.read()
tokens = nltk.word_tokenize(content)
tagged_tokens = nltk.pos_tag(tokens)
return tagged_tokens
Now, instead of having to open a file, read the contents and close the file, we can just call the function tag_tokens_file to do this. We can test it on a single file:
In [ ]:
filename = "../Data/dreams/vickie1.txt"
tagged_tokens = tag_tokens_file(filename)
print(tagged_tokens)
We can also do this for each of the files in the ../Data/dreams directory by using a for-loop:
In [ ]:
import glob
# Iterate over the `.txt` files in the directory and perform POS tagging on each of them
for filename in glob.glob("../Data/dreams/*.txt"):
tagged_tokens = tag_tokens_file(filename)
print(filename, "\n", tagged_tokens, "\n")
Now, we extend this code a bit so that we don't print all POS-tagged tokens of each file, but we get all (proper) nouns from the texts and add them to a list called nouns_in_dreams. Then, we print the set of nouns:
In [ ]:
# Create a list that will contain all nouns
nouns_in_dreams = []
# Iterate over the `.txt` files in the directory and perform POS tagging on each of them
for filename in glob.glob("../Data/dreams/*.txt"):
tagged_tokens = tag_tokens_file(filename)
# Get all (proper) nouns in the text ("NN" and "NNP") and add them to the list
for token, pos in tagged_tokens:
if pos in ["NN", "NNP"]:
nouns_in_dreams.append(token)
# Print the set of nouns in all dreams
print(set(nouns_in_dreams))
Now we have an idea what Vickie dreams about!
Exercise 1:
Try to collect all the present participles in the the text store in ../Data/Charlie/charlie.txt using the NLTK tokenizer and POS-tagger.
In [ ]:
# you code here
You should get the following list:
['boiling', 'bubbling', 'hissing', 'sizzling', 'clanking', 'running', 'hopping', 'knowing', 'rubbing', 'cackling', 'going']
In [ ]:
# we can test our code using the assert statement (don't worry about this now,
# but if you want to use it, you can probably figure out how it works yourself :-)
# If our code is correct, we should get a compliment :-)
assert len(present_participles) == 11 and type(present_participles[0]) == str
print("Well done!")
Exercise 2:
The resulting list verb_lemmas above contains a lot of duplicates. Do you remember how you can get rid of these duplicates? Create a set in which each verb occurs only once and name it unique_verbs. Then print it.
In [ ]:
## the list is stored under the variable 'verb_lemmas'
# your code here
In [ ]:
# Test your code here! If your code is correct, you should get a compliment :-)
assert len(unique_verbs) == 28
print("Well done!")
Exercise 3:
Now use a for-loop to count the number of times that each of these verb lemmas occurs in the text! For each verb in the list you just created, get the count of this verb in charlie.txt using the count() method. Create a dictionary that contains the lemmas of the verbs as keys, and the counts of these verbs as values. Refer to the notebook about Topic 1 if you forgot how to use the count() method or how to create dictionary entries!
Tip: you don't need to read in the file again, you can just use the list called verb_lemmas.
In [ ]:
verb_counts = {}
# Finish this for-loop
for verb in unique_verbs:
# your code here
print(verb_counts)
In [ ]:
# Test your code here! If your code is correct, you should get a compliment :-)
assert len(verb_counts) == 28 and verb_counts["bubble"] == 1 and verb_counts["be"] == 9
print("Well done!")
Exercise 4:
Write your counts to a file called charlie_verb_counts.txt and write it to ../Data/Charlie/charlie_verb_counts.txt in the following format:
verb, count
verb, count
...
Don't forget to use newline characters at the end of each line.
{kind=link}